參考
昨天講的非常隴統,以下讓我們從有幾種類型開始認識,Memory Barrier 有兩種類型,Compiler Barrier 以及 CPU Barrier
asm volatile("" ::: "memory");
lfence (asm), void _mm_lfence(void)
sfence (asm), void _mm_sfence(void)
mfence (asm), void _mm_mfence(void)
dmb (asm)
dsb (asm)
isb (asm)
CPU Barrier 會根據指令架構不同,有很大的差異
Compiler Barrier 與 CPU Barrier 的區別可以從下圖看出差別
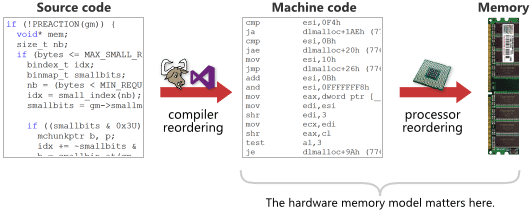
以下我們會重點探討 CPU Barrier 怎麼運作
參考 cpu 的記憶體架構,可以發現有 L1 Cache, L2 Cache, 主記憶體,總共三層記憶體,較新型的處理器可能還有 L3 Cache, L4 Cache,這邊並不探討多層 Cache 之間互相怎麼運作,只是用來解釋 CPU 有自己的 Cache,也就是每顆 CPU 的 Private Data,那麼 ...... 什麼時候要與主記憶體進行資料同步會是個大問題!
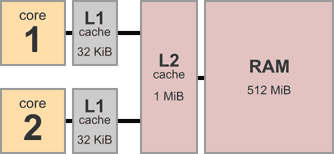
假設有兩個不同的 cpu 分別執行這兩段組語,我們對照到上面的記憶體架構,不難想像兩顆 CPU 之間不一直作記憶體同步的動作,結果高機率會有誤差
void thread1() {
asm("mov 1, [X]" // store to X
"mov [Y], r1" // load from Y
);
}
void thread2() {
asm("mov 1, [Y]" // store to Y
"mov [X], r2" // load from X
);
}
如果沒進行同步,兩顆 CPU 計算出的結果,X Y 值會完全不同,為了解決這個問題,已經有人將問題分為四種狀況,分別進行討論
下列四種狀況的命名是源自於順序,如:LoadLoad 表示專門處理兩個連續的 Load 指令所造成的 Memory Reorder 狀況
git pull,一直去跟雲端要資料,在我們的例子中,是指去主記憶體抓取資料,保證數值是目前最新的,以下的範例是再回傳數值前作更新if (IsPublished) // Load and check shared flag
{
LOADLOAD_FENCE(); // Prevent reordering of loads
return Value; // Load published value
}
git push 將資料存回雲端,在我們的例子中,是指把資料寫回主記憶體,對照到上一份程式碼,這表示要在 IsPublished 被設為 1 之前,寫回主記憶體Value = x; // Publish some data
STORESTORE_FENCE();
IsPublished = 1; // Set shared flag to indicate availability of data
LoadStore
其實就是指 Data Dependency
假設先載入一個變數到暫存器,接著打算作寫入的動作,把資料寫回主記憶體
如果寫入的動作,有使用到前一個載入的變數,那麼就要確定變數已經確實載入,才能執行寫入的動作
但這邊指的 Barrier 都僅限於 Private Data,只是強調在個別 CPU 中的順序不能亂掉,而不是像 StoreStore 一定要先寫回主記憶體
StoreLoad
將所有修改存回主記憶體,才繼續進行載入的動作,可以稱這樣的行為為「sequentially consistent」,所有指令都會按照撰寫順序進行
參考 Weak vs. Strong Memory Models(中文心得 浅谈Memory Reordering)
已經了解了有四種不同的狀況,那麼一般的機器,如果不特別作設定,會是哪一種記憶體排序呢?
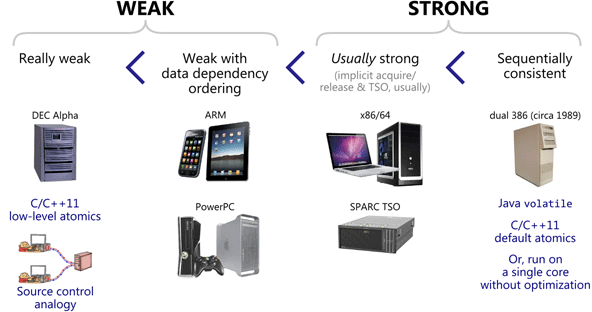
Really weak
完全不保證任何順序
Weak with data dependency ordering
保證 LoadLoad 的順序
Usually strong
保證 LoadLoad StoreStore LoadStore 的順序
Sequentially consistent
保證全部的順序
參考
#define _GNU_SOURCE
#include <assert.h>
#include <pthread.h>
#include <sched.h>
#include <unistd.h>
#include <stdio.h>
static pthread_barrier_t barr, barr_end;
volatile int x, y, r1, r2;
static void* thread1(void *arg)
{
while(1) {
pthread_barrier_wait(&barr);
x = 1; // store
//__asm__ __volatile__("mfence" ::: "memory");
r1 = y; // load
pthread_barrier_wait(&barr_end);
}
return NULL;
}
static void* thread2(void *arg)
{
while (1) {
pthread_barrier_wait(&barr);
y = 1; // store
//__asm__ __volatile__("mfence" ::: "memory");
r2 = x; // load
pthread_barrier_wait(&barr_end);
}
return NULL;
}
int main()
{
pthread_barrier_init(&barr, NULL, 3);
pthread_barrier_init(&barr_end, NULL, 3);
pthread_t t1, t2;
pthread_create(&t1, NULL, thread1, NULL);
pthread_create(&t2, NULL, thread2, NULL);
//int num = sysconf(_SC_NPROCESSORS_CONF);
int cpu_1 = 0;
int cpu_2 = 1;
cpu_set_t cs;
CPU_ZERO(&cs);
CPU_SET(cpu_1, &cs);
pthread_setaffinity_np(t1, sizeof(cs), &cs);
CPU_ZERO(&cs);
CPU_SET(cpu_2, &cs);
pthread_setaffinity_np(t2, sizeof(cs), &cs);
// wait result
while(1) {
// init variable
x = y = r1 = r2 = 0;
pthread_barrier_wait(&barr);
pthread_barrier_wait(&barr_end);
printf("r1 = %d, r2 = %d\n", r1, r2);
//assert(!(r1 == 0 && r2 == 0));
}
pthread_barrier_destroy(&barr);
pthread_barrier_destroy(&barr_end);
return 0;
}
CPU_SET 以及 pthread_setaffinity_np 將 thread 限制在不同的 cpu 上執行pthread_barrier 進行等待,方便進行觀察那我們要觀察的亂序執行在哪呢?把重點放在 thread1() 以及 thread2()
void thread1() {
.......
x = 1;
r1 = y;
.......
}
void thread2() {
.......
y = 1;
r2 = x;
.......
}
因為我們沒有使用任何 Lock,所以我們無法預測 r1 r2 究竟會等於多少,但可以知道的是,如果讓他按照順序執行,r1 r2 至少會有一個為一,不可能都為零
很遺憾的是,執行程式後會發現,居然有兩者皆為零的狀況產生,所以這時就可以使用到我們的 StoreLoad Barrier ,將以上兩個 Function 中的註解拿掉即可
Memory Barrier 這個鬼東西,我覺得很難理解,看了一堆心得我也搞不清楚有沒有解析錯誤,但如果要閱讀這系列文章,請務必要搞懂他
因為 Synchronization 的章節之後會有一兩個實作,如果沒有甚麼概念的話,就喪失了我們使用 C 語言來探討的意義了,乾脆使用較高階的語言來做研究,如: Python 來開發多線程的程式,他的 Queue 在文件中就直接就告訴你是 Thread-Safe,什麼都幫你處理好了,要研究原理的話,大概只能研究 GIL(Global Interpreter Lock) 了吧
扯太遠了,反正有什麼 Lab 取決於我看完資料有沒有成功理解,我會盡量選擇不要實作,閱讀別人撰寫的程式碼就好,我只會確認程式是否可以正確執行,可能撰寫的題目是,從 Blocking 出發到 Concurrent,是一個如何開發多線程程式的各種範例探討,會至少分成兩篇文章作探討
時間夠的話,會有一個 Lab 把 Multi-Process 也牽連進來,因為之前去科技公司面試的時候,有被問到一題,Process 之間如何做溝通,但坦白講除了 Shared Memory 之外,我一個都沒用過,所以答得不太好,總之,先把 Thread 的部分都先搞定,再來想有什麼題目適合當作 Lab 吧
BTW 我最原始想寫的 Lab 是開發一個閹割版的 aria2,可是這感覺會浪費一堆時間在搞各種連線的協 ......

